n8n实战033,全自动短剧拆分场景、服化道、TTS台词(附完整提示词、代码)
- 2026-06-22 09:30:57

兄弟们,今天我们就来详细的介绍第一个子工作流,拆分故事,只要你录入一个小说,就能自动按照场景将故事拆分开,同时也能按照旁白、角色来拆分tts台词,方便我们后续按照拆分的故事绘制宫格图和情绪化配音
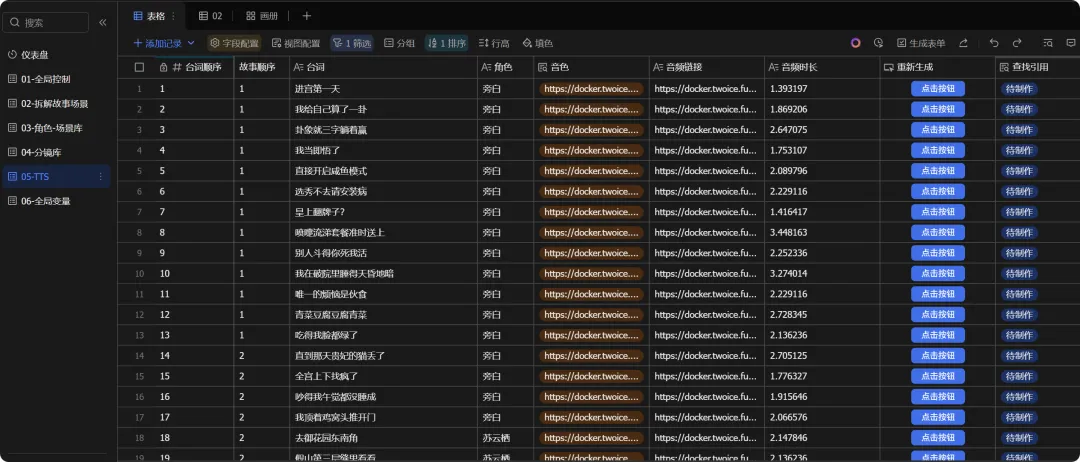
今天这一期实战,二冰直接把整套短剧脚本拆解工作流甩出来。不管是场景切换、道具识别,还是台词自动切分,全给你们整得明明白白的。废话少说,直接开整!
如果还没看过前两期的兄弟们可以移步查看
n8n实战031,全自动AI漫剧系统:文案到剪映草稿,一键搞定,内附10个工作流
n8n实战第32期,手把手教你配置AI漫剧“大脑”:飞书多维表格全解析!直接抄作业
本套工作流系统做的视频效果如下
一、你需要准备什么?
搞定这个自动化工作流,兄弟们先把这几个凭证准备好:
1. bizyair 跟硅基流动是一家的
这是二冰现在所有的生图生视频工作流用的api,国内的中转api二冰基本上研究一个遍了,最后结论是硅基流动牛逼,兄弟们自己看下价格吧
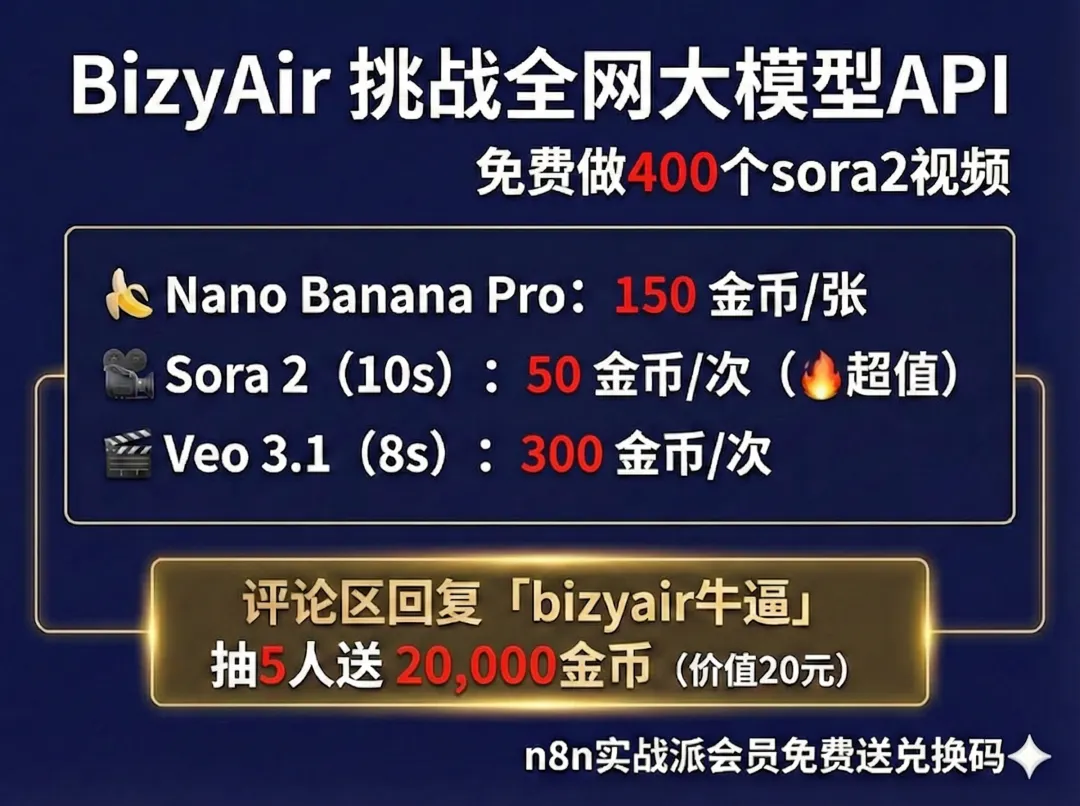
二冰真不是托,同时也感谢bizyair官方认可,给了二冰一些兑换码,可以兑换20000金币价值20元,够你做400个sora2视频,评论区评论「bizyair牛逼」,二冰选五个给发兑换码,
注:实战派会员免费得兑换码
https://bizyair.cn/
2. 硅基流动 API Key
二冰用的大模型都是硅基流动的,大家可以点一下我的邀请链接,咱们一人获得2000万token,绝对够你用好久好久好久
https://cloud.siliconflow.cn/i/ttf52sDl
3. 飞书自建应用(需开启多维表格权限) 4. 企业微信群机器人 Webhook 5. n8n 社区节点: n8n-nodes-feishu-lite(飞书节点必备)
以上准备工作的详细图文教程(如怎么申请Key、怎么建应用),二冰都整理在飞书文档里了,还没搞定的兄弟先去看文档,搞定再回来接着整:
https://ai.feishu.cn/docx/FjX0dIyw4onA4ZxZUFzcczXrnyd?from=from_copylink
二、这个工作流是怎么跑的?(逻辑解析)
这个工作流的逻辑贼硬核,主要分三步:
1. 监听与清洗:通过 Webhook 或子流程接收原始故事文本,先进行结构化清洗,确保 AI 能读懂。 2. AI 深度拆解:调用硅基流动的高端模型(如 GLM-4/5),按照“分镜/场景/台词”三级结构进行物理拆分,同时识别关键道具和角色心声。 3. 自动化落库:将拆好的脚本全自动写入飞书多维表格,并生成全局摘要和单场景摘要,方便后续直接喂给生图工具。
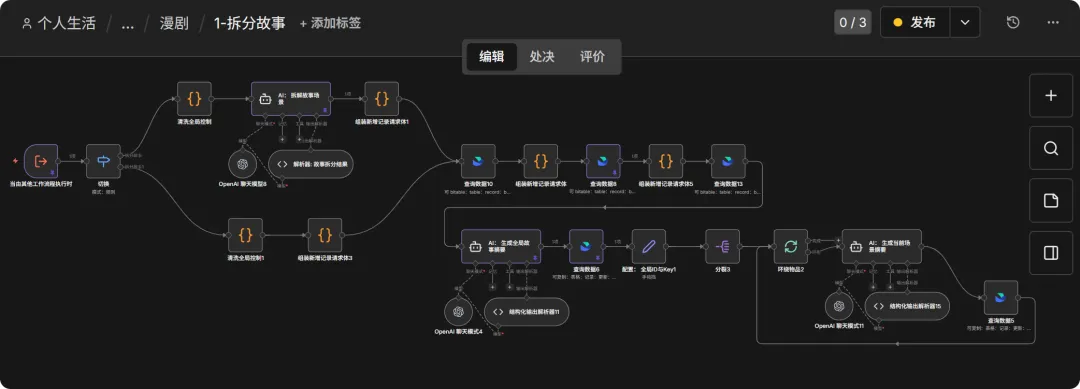
三、节点详细配置(全流程拆解)
兄弟们注意了,这个流程一共 23 个节点,咱们一个一个拆,一个都不能少!
1. 外部工作流触发 (Execute Workflow Trigger)
这是整个流程的入口,方便被其他主流程调用。
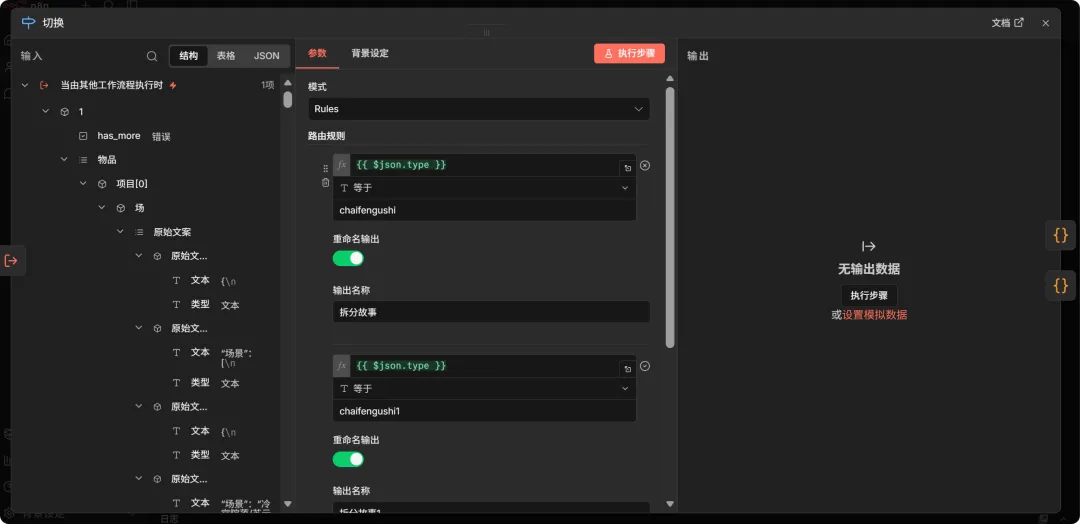
2. 任务类型分发 (Switch Node)
这里用了一个 Switch,判断进来的任务是批量拆解还是精细化拆解。
3. 原始文案清洗 (Code Node)
把飞书里拿到的乱七八糟的文案字段提取出来,统一转换成干净的 story 文本。
// ============================================================
// 1. 获取输入数据并提取 records 数组
// ============================================================
const inputData = $input.first().json;
// 根据新结构,数据在键 "1" 的 items 属性中
const records = inputData["1"]?.items || [];
// ============================================================
// 2. 辅助函数:安全提取文本或链接
// ============================================================
/**
* 提取飞书字段文本:支持数组对象拼接、单个对象提取或纯字符串
*/
const getText = (field) => {
if (!field) return "";
if (Array.isArray(field)) {
return field.map(item => item.text || "").join('');
}
return typeof field === 'object' ? (field.text || "") : field;
};
/**
* 提取链接:优先提取 link 属性,其次提取 text
*/
const getLink = (field) => {
if (!field) return "";
return field.link || field.text || (typeof field === 'string' ? field : "");
};
// ============================================================
// 3. 处理数据并构建输出
// ============================================================
return records.map(record => {
const fields = record.fields || {};
return {
json: {
// 1. 处理原始文案:自动拼接数组中所有 text
story: getText(fields['原始文案']),
// 2. 处理编号:提取第一个 text
id: getText(fields['编号']),
// 3. 处理背景音乐:提取 link 属性
bgm: getLink(fields['背景音乐']),
// 4. 处理音色:适配数组或纯字符串路径
voice: getText(fields['音色']),
// 5. 处理风格:直接获取
art_style: fields['风格'] || "",
// 6. 记录 ID
record_id: record.record_id
}
};
});4. AI 场景深度拆分 (AI Agent)
添加AI agent节点
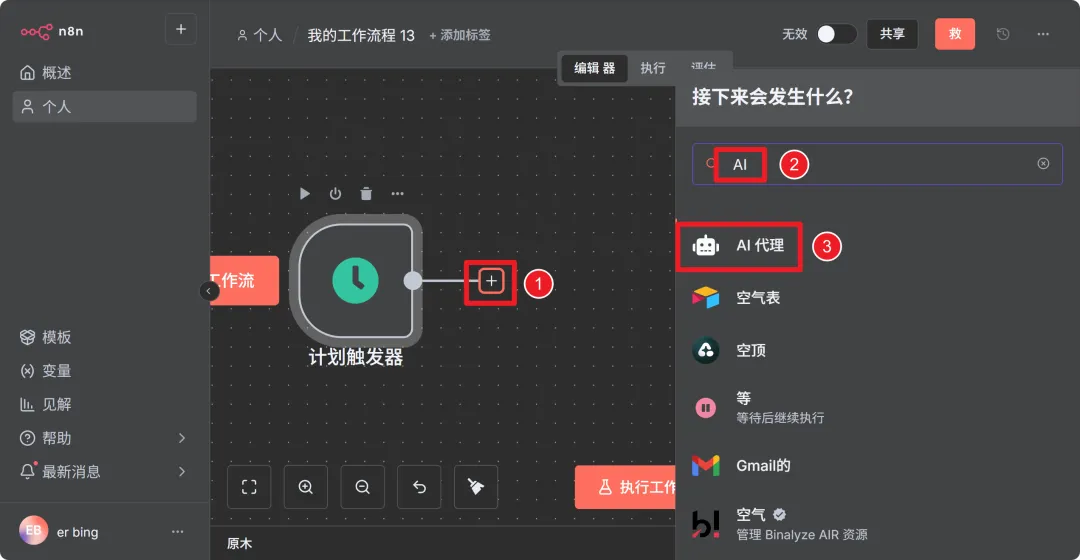
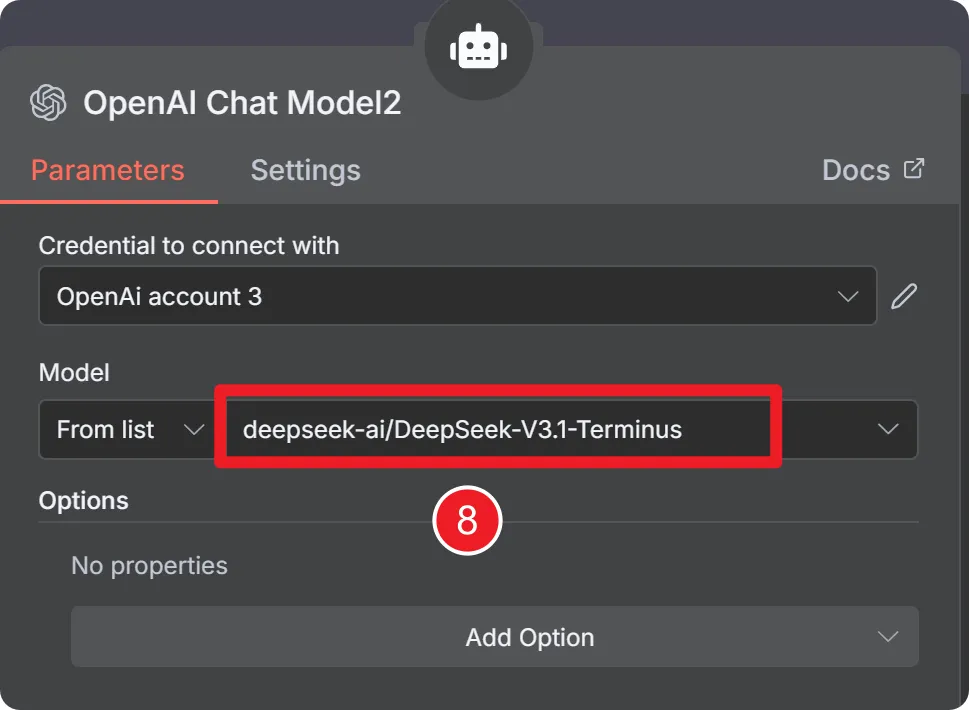
配置凭据
配置凭据后,选一个硅基流动的模型就行了
# Role
你是一位**顶级短剧/漫剧内容架构师**,擅长将碎片化的网文剧本转化为具备**高度电影感**和**逻辑闭环**的视觉脚本。
## 核心逻辑
**TTS = 视频的灵魂轴线**
你生成的 `tts_lines` 将直接驱动分镜绘制。你必须保证:**画面感、节奏感、字数适配字幕、以及全局逻辑的连贯性。**
---
## 一、 场景拆分与连贯性规则
1. **物理拆分原则**:空间切换(室内到室外)、时间跨度(白天到黑夜)、环境状态突变(完好到废墟)必须拆分。
2. **叙事桥梁(Narrative Bridge)**:
* **禁止生硬跳跃**:每一场戏的开头旁白,必须承接上一场的结尾动作或状态。
* **时间/因果交代**:通过旁白交代时间流逝(如:“半月之后,摘星楼已高耸入云”)。
## 二、 剧情完整性与逻辑闭环(Global Logic Check)
1. **全局扫描**:在动笔拆分前,必须纵观全局,识别出剧本中的**“核心锚点”**(如:亡国倒计时、系统点数、主角的隐藏身份)。
2. **关键信息埋点**:
* **严禁删减核心设定**。如果后期剧情提到了倒计时,前面的旁白必须清晰交代“系统面板”或“倒计时开启”的信息。
* 保证**“前有因,后有果”**,严禁出现后面剧情突然冒出前面从未交代的关键要素。
## 三、 关键物品筛选(Strict Assets Only)
1. **判定标准**:该物品是否跨越了**两个或多个场景**?如果下一个场景它变了样子,观众会觉得穿帮吗?
2. **资产级定义**:角色绑定装备(专属武器、工具带)、跨场景核心道具(系统终端、唯一信物)。
3. **垃圾过滤**:单场景内的陈设(桌椅)、消耗品(食物、烟)、临时工具(螺丝刀、水流计)一律**不写**。
4. **宁缺毋滥**:如果没有跨场景资产,`key_items` 必须保持为空 `[]`。
## 四、 TTS 生成极致规范(Subtitle & Novel Style)
1. **字幕黄金区间**:单条 `text` 严格控制在 **15-20 个汉字** 之间。
2. **自然叙事语感**:使用小说化的描述。禁止“特写、镜头、画面”等术语。
3. **系统语境转化**:将硬核的“系统提示音”转化为具有文学感的旁白或主角心声。
* *错误*:`系统音:暴行点增加500。`
* *正确*:`脑海中机械音响起,暴行点数再次疯狂跳动。`
4. **先铺后说**:先用旁白描述神态/动作铺垫情绪,再跟上纯净的台词(去掉“他说道”等赘余)。
---
## 五、 输出数据结构 (JSON Only)
```json
{
"scenes": [
{
"scene": "准确地点名称",
"story": "该场景的核心剧情概括",
"characters": ["角色A", "角色B"],
"key_items": ["必须是跨场景出现的资产名称"],
"tts_lines": [
{ "role": "旁白", "text": "富有美感且具备转场逻辑的描述,20字以内。" },
{ "role": "角色名", "text": "纯对话内容,20字以内。" }
]
}
]
}
```
## 六、 任务执行
请纵观全局,处理以下文本。**特别注意:确保“倒计时”、“系统奖励”等核心设定在第一幕就得到清晰展现,保证前后逻辑严密:**
{{ $('清洗全局控制').item.json.story }}5. 硅基流动大模型支撑 (Language Model)
这里二冰建议用 GLM-4 或者更高版本的模型,处理长文本贼稳。
6. 结构化输出解析 (Output Parser)
告诉 AI 必须按我给定的 JSON 格式返回,不然飞书接不住。
[
{
"scene": "场景名称(地点)",
"story": "原始剧本内容...",
"characters": ["角色A", "角色B"],
"key_items": ["道具A"],
"tts_lines": [
{
"role": "旁白",
"text": "林陌坐在角落,手里那杯咖啡微微颤抖。"
},
{
"role": "王阔",
"text": "哟,这不是林大少吗?"
},
{
"role": "旁白",
"text": "林陌握紧了拳头,指节因为用力而发白。"
},
{
"role": "林陌",
"text": "闭上你的嘴。"
}
]
}
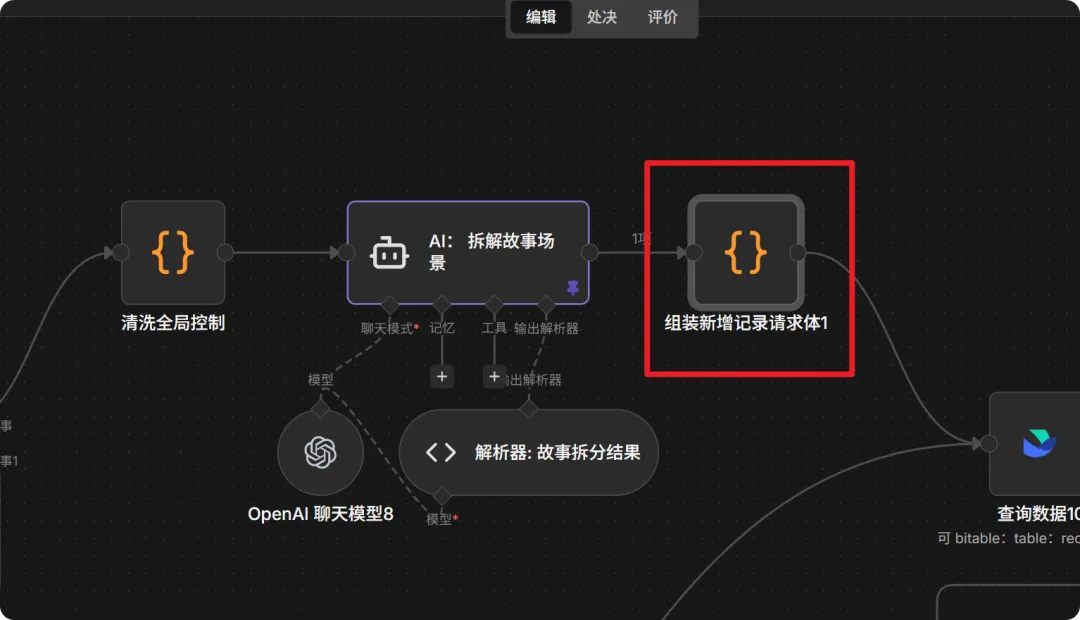
]7. 组装台词记录 (Code Node)
把 AI 生成的台词列表按顺序排好,准备批量怼进飞书。
// ============================================================
// 1. 获取输入数据与上下文
// ============================================================
// 注意:根据你的截图,最外层是数组,里面包裹着 output 对象
const inputItem = $input.first().json;
const scenes = inputItem.output || [];
// 获取全局项目ID (尝试从上游节点获取,如果获取不到则使用默认值)
let globalId = "Unknown";
try {
// 请确保引用的节点名称正确
const globalNode = $('清洗全局控制').first();
if (globalNode && globalNode.json) globalId = globalNode.json.id;
} catch (e) {
console.log("未找到全局ID,使用默认值");
}
// ============================================================
// 2. 初始化全局变量
// ============================================================
let allRecords = [];
let globalLineCounter = 1; // 🎯 核心逻辑:台词顺序从1开始,跨场景累加
// ============================================================
// 3. 遍历逻辑 (直接使用 tts_lines)
// ============================================================
scenes.forEach((sceneItem, sceneIndex) => {
// A. 获取该场景下的拆分台词列表
// 你的上游节点已经完美拆分好了,直接用
const lines = sceneItem.tts_lines || [];
// B. 获取其他元数据
const currentSceneName = sceneItem.scene || "";
// 将关键道具数组转为字符串数组(飞书格式)或直接使用
const currentProps = sceneItem.key_items || [];
// C. 遍历每一句台词
lines.forEach((lineObj) => {
const role = lineObj.role || "旁白";
const text = lineObj.text || "";
// 跳过空内容
if (!text.trim()) return;
// --- 组装 Feishu Record ---
allRecords.push({
"fields": {
"编号": globalId,
// 故事顺序: 对应大场景的 Index (1, 2, 3...)
"故事顺序": String(sceneIndex + 1),
// 🎯 全局台词顺序: 1, 2, 3... 一直累加,使用数字类型
"台词顺序": globalLineCounter++, // 直接使用数字,不带双引号
// 核心内容
"台词": text,
// 角色: 飞书多选/人员字段通常接受数组,或者是字符串
// 如果飞书字段是"文本",直接用 role;如果是"单/多选",用 [role]
"角色": role,
// "场景": currentSceneName,
// 关键道具
// "关键道具": currentProps
}
});
});
});
// ============================================================
// 4. 返回结果
// ============================================================
return {
"records": allRecords
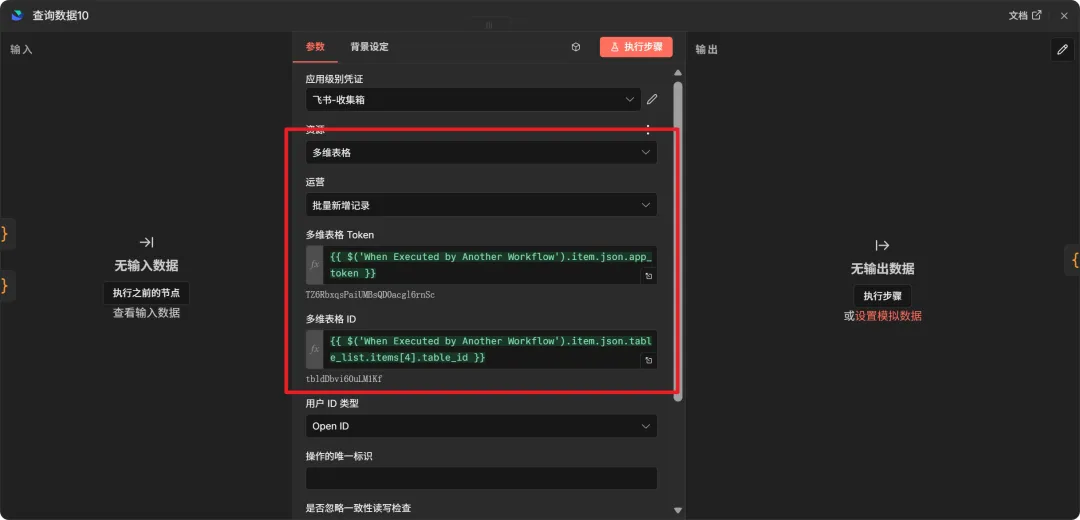
};8. 写入分场台词表 (Feishu Node)
这里用的是多维表格的批量新增记录
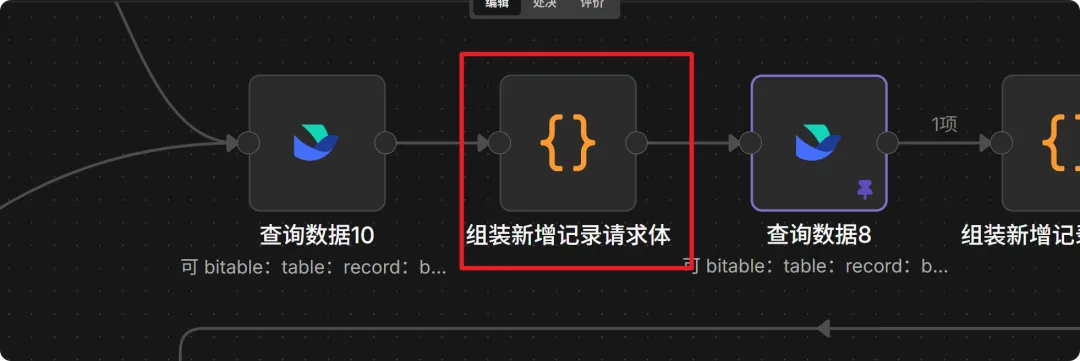
9. 组装场景/角色请求体 (Code Node)
这个节点负责把拆出来的资产(角色、道具)去重归类。
/**
* 优化后的数据转换脚本
* 适用场景:将 AI 拆解的场景数据映射至飞书多维表格
*/
// 1. 获取输入节点数据
const aiNode = $('AI: 拆解故事场景').first()?.json;
const globalControlNode = $('清洗全局控制').first()?.json;
// 2. 获取全局 ID (增加多种常见字段名兼容)
const globalId = globalControlNode?.id || globalControlNode?.record_id || "未定义ID";
// 3. 提取场景数组 (核心修复)
// 根据你提供的 JSON 结构: [{ "output": [...] }]
let rawScenes = [];
if (Array.isArray(aiNode)) {
// 处理结构: [{ "output": [...] }] 或直接是数组
rawScenes = aiNode[0]?.output || aiNode;
} else if (aiNode?.output) {
// 处理结构: { "output": [...] }
rawScenes = aiNode.output;
} else if (aiNode?.data) {
rawScenes = aiNode.data;
}
// 确保 rawScenes 最终是数组
const scenes = Array.isArray(rawScenes) ? rawScenes : [];
// 4. 如果没有有效数据,返回错误提示记录
if (scenes.length === 0) {
return {
"records": [{
"fields": {
"编号": globalId,
"场景": "错误:未解析到有效场景数据",
"故事": `输入结构异常: ${JSON.stringify(aiNode).substring(0, 100)}`
}
}]
};
}
// 5. 转换并映射字段
const records = scenes.map((item, index) => {
return {
"fields": {
"编号": globalId,
"故事顺序": (index + 1).toString(), // 飞书数字字段建议转为 String 以匹配部分文本映射
"场景": item.scene || item.场景 || "未命名场景",
"故事": item.story || item.故事 || "无内容",
// 数组字段处理:飞书多维表格的多选/人员字段通常接受 Array<String>
"角色": Array.isArray(item.characters) ? item.characters :
(item.角色 ? (Array.isArray(item.角色) ? item.角色 : [item.角色]) : []),
"关键道具": Array.isArray(item.key_items) ? item.key_items :
(item.关键道具 ? (Array.isArray(item.关键道具) ? item.关键道具 : [item.关键道具]) : [])
}
};
});
// 6. 返回飞书 API 标准格式
return { "records": records };10. 写入资产库 (Feishu Node)
将提取出的场景名称、角色名字批量新增斤飞书多维表格。
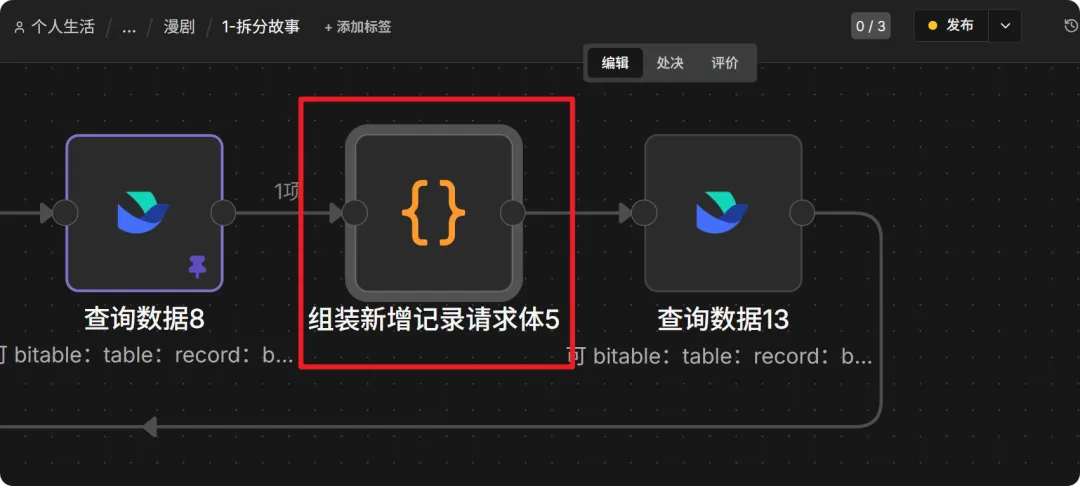
11. 组装场景详情记录 (Code Node)
把具体的场景描述和故事梗概打包。
12. 写入故事场景表 (Feishu Node)
同样是批量新增操作,把每一场戏存起来。
13. 全局故事摘要生成 (AI Agent)
你是一位专业的文本摘要专家。请为以下章节内容生成一个简洁的摘要,要求:
1. 字数控制在200字以内
2. 准确概括故事的核心发展
3. 包含关键事件和转折点
章节内容:
{{ $('清洗全局控制').item.json.story }}14. 摘要模型支撑 (Language Model)
用高性能模型来总结剧情精髓。
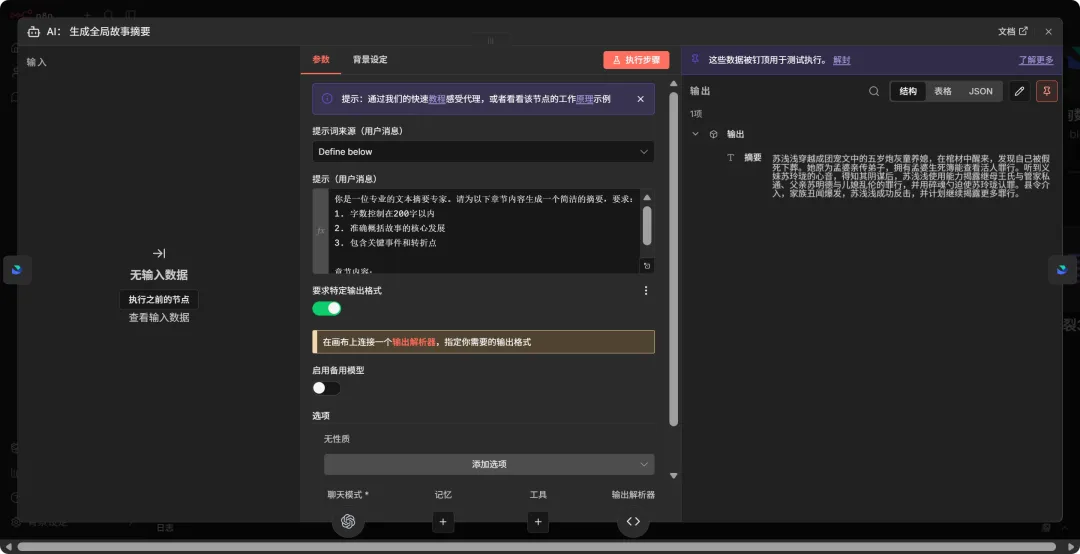
15. 全局摘要解析 (Output Parser)
结构化全局故事的总结。
16. 更新全局摘要字段 (Feishu Node)
用feishu-lite节点的Update操作,把需要写入的变量,写回飞书多维表格。

17. 变量参数配置 (Set Node)
锁定当前任务的全局 ID 和关键 Key,防止循环的时候跑串了。
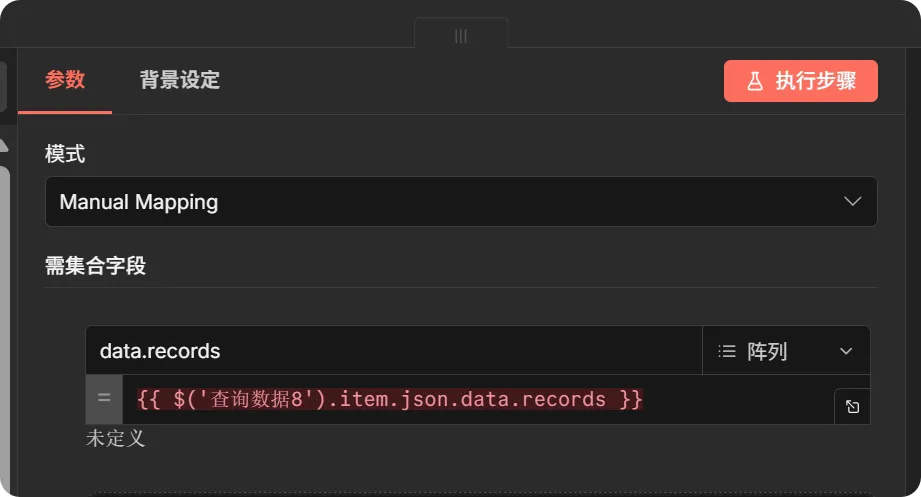
18. 数据列表拆分 (Split Out Node)
把飞书查回来的记录数组拆开,准备进循环。
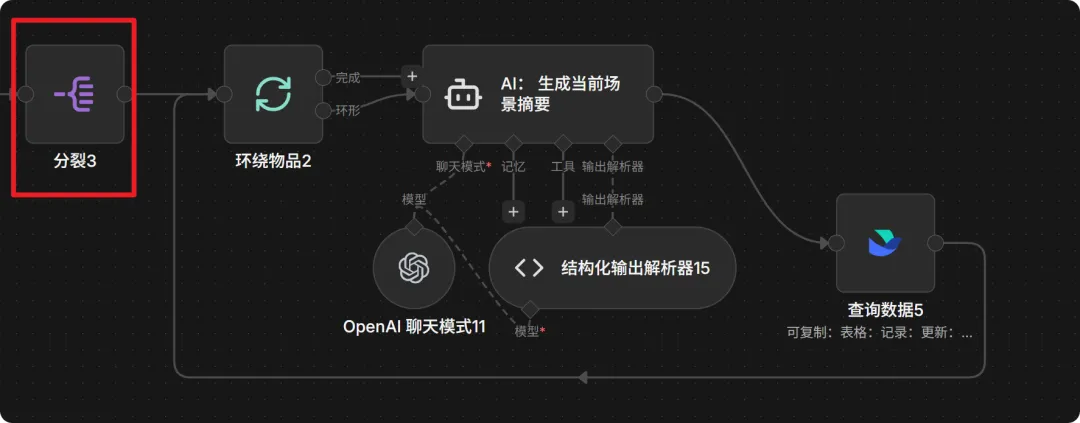
19. 场景循环处理 (Split In Batches Node)
一个场景一个场景地过,AI 挨个给场景写摘要。
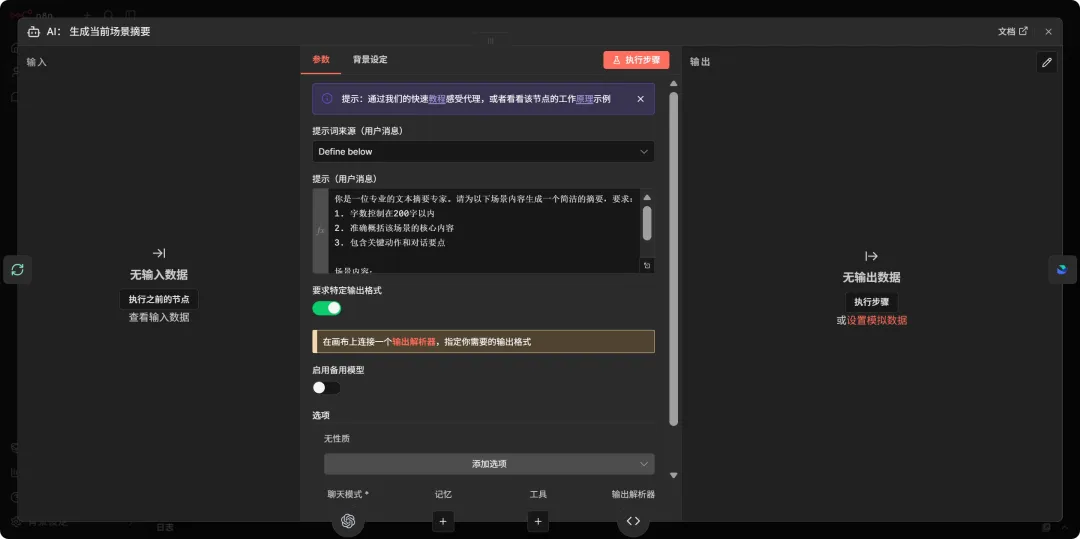
20. 逐个生成场景摘要 (AI Agent)
你是一位专业的文本摘要专家。请为以下场景内容生成一个简洁的摘要,要求:
1. 字数控制在200字以内
2. 准确概括该场景的核心内容
3. 包含关键动作和对话要点
场景内容:
{{ $json.fields['故事'] }}21. 循环内模型支撑 (Language Model)
给每个场景的小摘要提供算力。
22. 循环内结构化输出 (Output Parser)
输出每一场的 Summary。
23. 回写单场摘要到飞书 (Feishu Node)
用feishu-lite节点的Update操作,把需要写入的变量,写回飞书多维表格。

四、 运行测试
输入内容点一下拆分故事
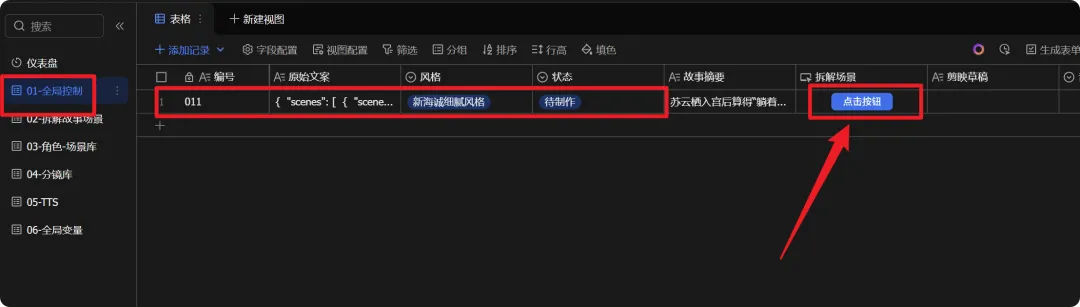
这样你就会获得
1、拆分场景表格
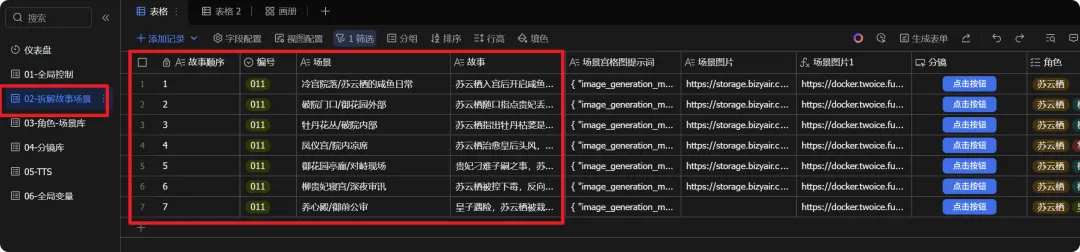
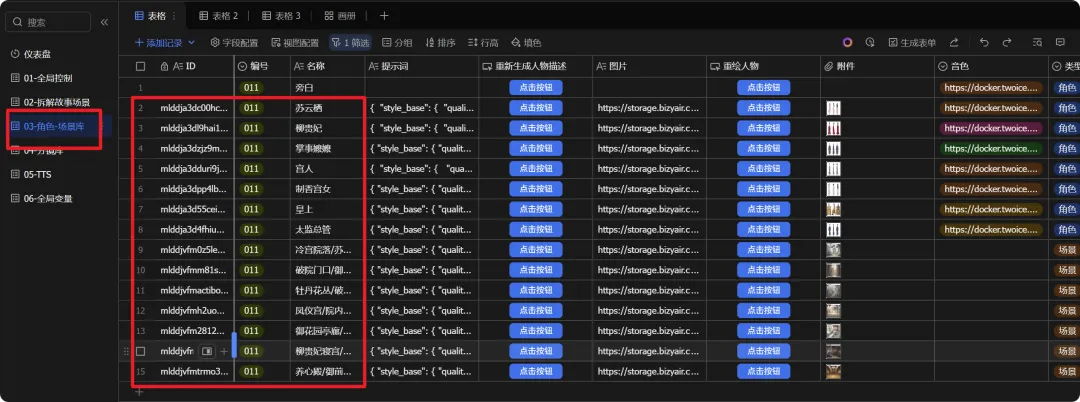
2、服化道表格
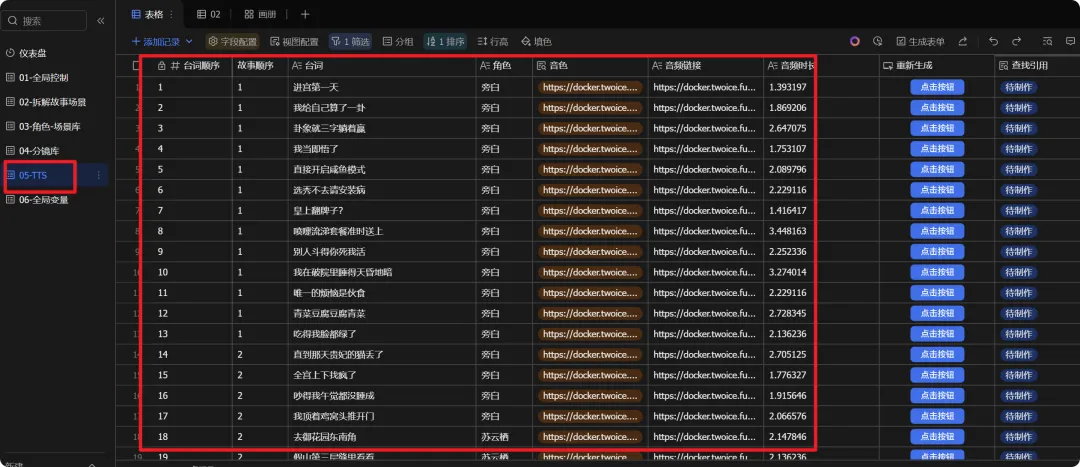
3、tts表格
五、 源码与后续
今天的项目有时间也会放到我们自己开发的n8n托管平台上跑,挨个对接确实很费精力
在线网址:http://szp.qazz.site/
因为跑的是我们几个人自己的nas,担心被别人乱用,所以设置了积分,每天可以领点积分,反正基本就够你跑几次了,试跑看效果绝对够用了
兄弟们用着好用可以给宣传宣传
本期实战涉及到的http请求接口详细参数、代码节点详细代码、提示词等已更新到飞书文档,兄弟们自行移步查看:
https://ai.feishu.cn/docx/Crzfdb5shoYN0DxYPSxc21CNnyh?from=from_copylink
本期分享就到这,下期我们拆解服化道工作流!
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 短剧全集【她曾如天光般明亮】(全剧后续/完整版)在线看全集大结局!抢先看完
- 热播短剧《桃烬九重天》1-103集/全集/大结局
- 爆火!短剧《月光永不坠落》完整版1-86集(后续/大结局/合集)
- 最新短剧【我的神明老公】(全剧后续/完整版)在线看全集大结局!抢先看完
- 工伤预防 · 桂在行动丨微短剧系列之《机械制造篇:瞬间的疏忽》
- 要追看短剧《霸王餐风波》1-109集(后续合集/完整版)
- 短剧全集【雾沉星未眠】(全剧后续/完整版)在线看全集大结局!抢先看完
- 治愈好看短剧《春夜难缠》1-102集(合集/完整版)
- 必追!好看短剧《桃烬九重天》1-98集(后续合集/完整版/大结局)
- 好看短剧《相亲相出个总裁妹妹》1-66集(合集/完整版)
