一集AI短剧从剧本到成片,成本不到500元,我们是怎么做到的
- 2026-06-22 02:08:08

上个月有个做传统短剧的团队来找我们,说一集拍下来光演员和场地就花了四五千。
我说我们做同等时长的AI仿真人短剧,成本不到500。
他不信。
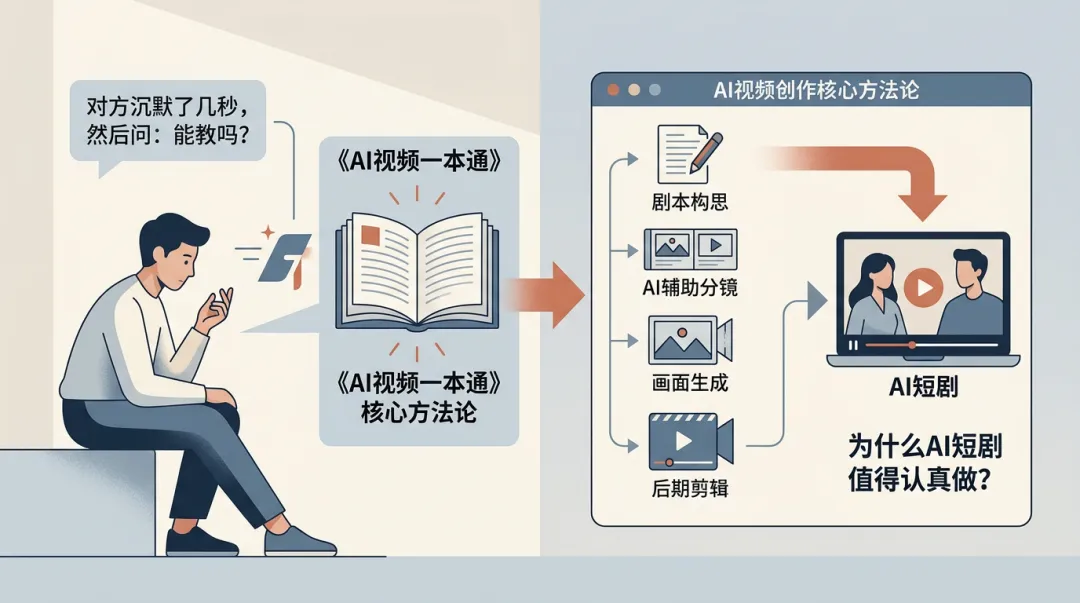
我把制作流程拆给他看了一遍,他沉默了几秒,然后问了一句:"这些你们课里教不教?"
教。
而且我们把核心方法论全写进了《AI视频一本通》这本书里。
今天先拆一部分出来。

以前做AI短剧,最痛苦的是"手搓"
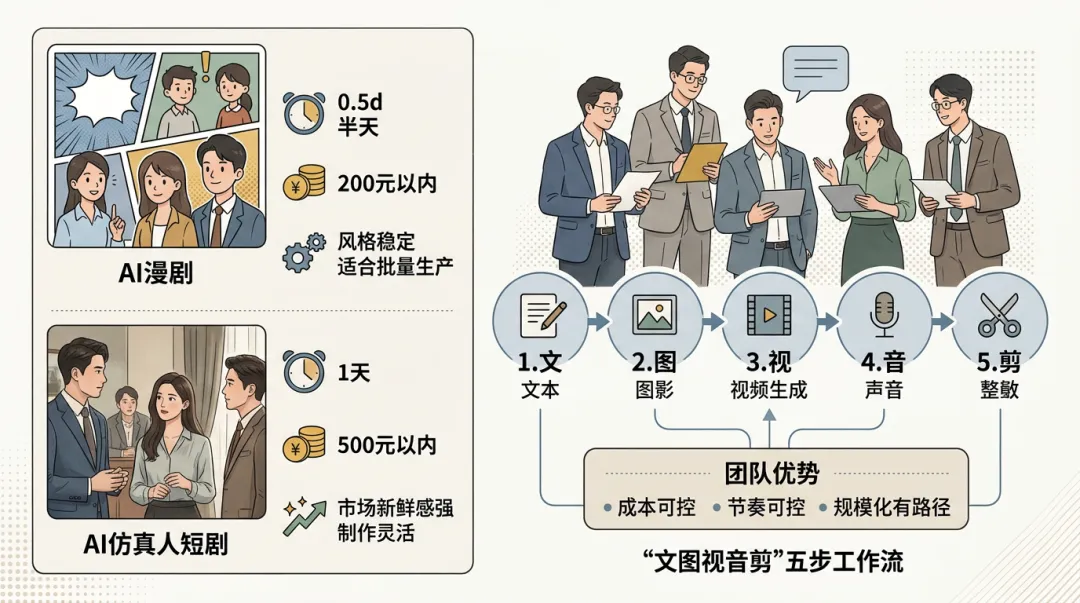
说实话,半年前我们做AI短剧的时候,流程还是"文-图-视-音-剪"五步。
每一步都要花大量时间。
特别是"图"这一步。
每一张分镜图都要用即梦或者MJ反复抽卡,一张不满意就重来,有时候一个角色的正脸特写就要抽十几次。
然后再用PS修修补补,确认没问题了才拿去做图生视频。
我们内部管这叫"手搓流",搓到凌晨三点是常有的事。
但今年开始,情况彻底变了。
随着Seedance 2.0和可灵3.0推出了"参考生视频"和"全能参考"模式,分镜图这一步变得不那么必要了。
只要提前准备好角色和场景的资产图,直接输入提示词就能生成完整的视频片段,自带运镜切换、自带台词口型、自带环境音效。
工作流从"文-图-视-音-剪"变成了"文-资-音-剪"。这不是小优化,是流程级的变化。
"参考生视频"为什么是核心
很多人问我做AI短剧最关键的技术是什么。
我以前会说角色一致性。
现在我会更精确地说:参考生视频。
参考生视频的意思是,你上传角色、场景、道具的参考图,AI学习这些图里的面部特征和风格信息,然后在完全脱离原图构图的情况下,生成一段包含这些角色的全新视频。
以前你想生成一段对话戏,要先出男主正面分镜图、女主正面分镜图、男主侧面图、女主反应镜头图,每张都要单独生成、单独调整,光这些图就要花半天。
现在呢?
把角色资产图上传,写一段提示词,模型帮你自动完成正反打镜头切换、表情特写推拉,十几秒一气呵成。
而且最让人兴奋的是"音画同出"。你在提示词里写上台词,用双引号括起来,模型会同步生成角色说话的口型、环境音效、甚至脚步声。
以前要专门做的配音和对口型环节,现在直接省掉了。
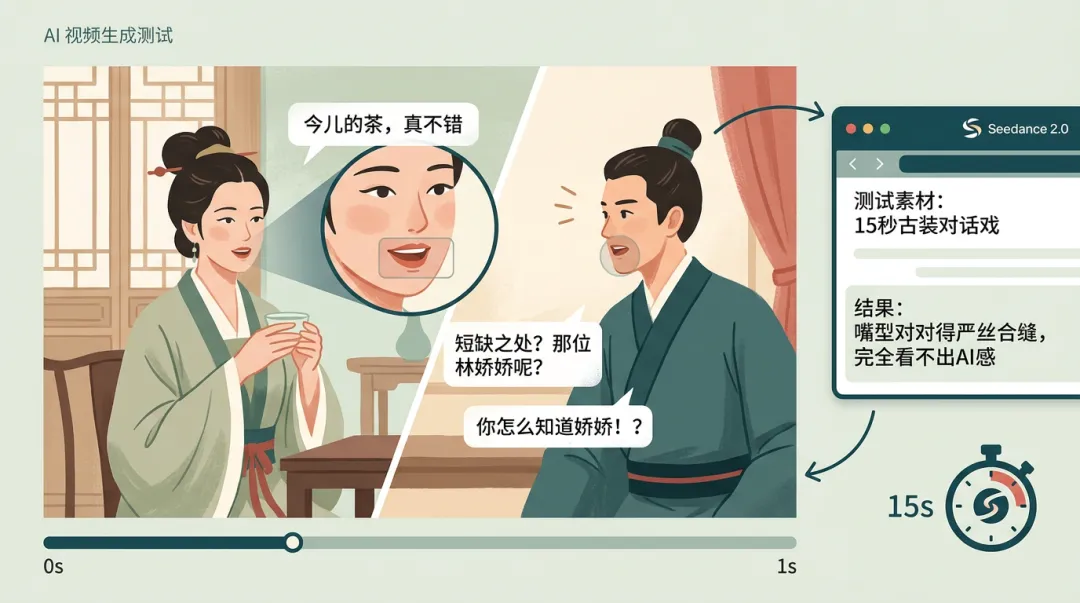
我们在书里拿了一段古装对话戏做测试。
一段15秒的素材,两个角色面对面交谈,台词是"今儿的茶,真不错""短缺之处?那位林娇娇呢?""你怎么知道娇娇!?"
Seedance 2.0出来的效果,台词没有任何嘴瓢,嘴型对得严丝合缝,完全看不出AI感。
越测越不敢睡。
但这里面有一个现实问题
效果好不代表每个模型都能直接用。
Seedance 2.0的全能参考模式效果最好,但它对真人面孔的审核非常严格。
你直接上传写实风格的角色图,大概率被拦截。
我们在书里教了几种绕过方法:局部面部转绘、平台站内洗图、文本脱敏。
这些方法经过反复测试,成功率很高。
可灵3.0的Omni模型走的是另一条路。
它支持创建"主体库",上传一段3到8秒的角色视频,模型提取面部特征和声音音色,后续生成视频的时候直接@角色就行。
不管怎么切镜,人脸始终统一。
这个在做连续剧情的时候非常关键。
但可灵有一个坑很多人不知道。
如果你只是把剧本文本直接丢进提示词框,不开"自定义分镜",即使勾了"智能分镜",也很可能出来一个完全不切镜的长镜头。
15秒一镜到底,人物画面不崩才怪。
你必须手动把提示词按时间轴拆分:0到3秒什么景别什么动作,3到7秒切到什么镜头。写清楚了,可灵出来的效果非常稳。
写模糊了,就是赌运气。
Vidu Q3速度最快,5秒以内的人物表演效果很好。
但它目前的Q3参考生视频还没全量开放,做仿真人短剧的话暂时只能当补充。
角色资产,依然是命门
虽然工作流变了,但有一件事从来没变过。
AI短剧的核心不是视频生成模型有多强,而是角色资产做得有多好。
如果你的角色只有一张正面照,换个角度模型就"不认识"了。
你用再好的模型、写再精确的提示词,角色一致性也会崩。
我们在书里给出的资产标准是:正面全身照加多角度参考图加表情变体。

这三样齐了,角色一致性基本就稳了。
生成工具方面,z-image的角色一致性目前最强,它有专门的"角色参考"功能,上传一张正面照就能自动生成多角度视图。
即梦免费,适合快速出图验证方向。
香蕉风格库丰富,适合漫剧风格。
做AI短剧最容易犯的错误,就是花大量时间调视频参数,而忽略了前期的角色资产准备。
卡在视频生成这一步的团队,通常是角色资产没做扎实。

过肩镜头和轴线关系
这个细节很多做AI短剧的人不太注意,但它决定了你的片子看起来"像不像那么回事"。
做对话戏的时候,正反打镜头需要遵循"轴线规则"。
简单说就是:两个角色之间有一条假想的直线,你的镜头必须始终在这条线的同一侧。
如果越过这条线,观众看起来就会觉得人物的位置关系突然反了,特别出戏。
我们在SOP里的建议是:人物站位一旦确定,整场戏尽量不做太大变动。
全景图用来交代位置关系,其余画面以中近景为主,这样能减少两人同框时出现问题的概率。
过肩镜头的提示词写法也有讲究。
基本结构是"画风+过肩镜头+景别+站位+主体描述+环境氛围"。
要在提示词里明确写"前景画面的边缘是某角色模糊的肩膀,聚焦在后景的另一角色的脸"。
这些东西在书里的"视频模型实战"和"视听语言"章节都有展开讲。
关于这本书
说实话,《AI视频一本通》里这些内容,很多都是我们做了十几部AI短剧之后才总结出来的。
两年时间,从漫剧到仿真人短剧,从手搓流到资产驱动,从每集花几天到现在半天出片。
走了很多弯路,也踩了很多别人不会告诉你的坑。
明天(3月17日),这本书正式在京东上线,电子工业出版社出版。
明晚我们有直播,会聊书里的内容,也会现场演示AI短剧的制作流程。
来直播间的朋友有三个福利:专属电子签名版、价值199元的AI短剧课程、OpenClaw龙虾安装教程。
添加「西堂」,输入暗号「AI书籍」,直接拉你进直播间。

感谢你看到最后。
推荐阅读
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 《AI电影短剧必然取代真人版电影短剧》
- 【影视制作】|《任运版白蛇传·真心无界》短剧制作(首集)
- 精彩热播短剧《月光永不坠落》1-99集(合集/完整版/大结局)
- 精彩热播短剧《白骨大圣》1-99集(合集/完整版/大结局)
- 精彩后续《明月入君怀》1-99集(短剧合集/完整版/大结局)
- 75岁刘晓庆演短剧被全网群嘲,她晒书法、赞自己、穿上心理防弹衣
- 打造微短剧全产业链新高地 东方智媒城推出AIGC视听创制基地与孵化器集群
- 《清风说》系列短剧:表面文章
- 治愈短剧《从此星河不相逢》后续1-118集(合集/大结局)
- 精彩后续短剧《陆太太今天离婚了》大结局1-90集(后续/完整版/)
